主页 > imtoken制作冷钱包 > 区块链-比特币挖矿原理
区块链-比特币挖矿原理
目录:
目录
概览
分布式账本是比特币系统的三大组成部分之一,分散在比特币网络的各个节点上,每个节点争取记账权的过程就是我们通常所说的挖掘。
从计算机或程序代码的角度来看,挖矿就是进行算法运算,反复执行Hash函数并检测执行结果的具体过程。
比特币挖矿基于POW共识机制。从2008年创世区块开始,挖矿逐渐从CPU的小作坊发展到GPU挖矿,最终进化到ASIC时代(矿池、专业大型矿机)。下面将简要分析其逻辑和技术实现。挖矿的演进不仅是硬件的发展比特币挖矿网站,也是软件的推动,软硬件对接协议的演进。
挖矿
在讨论原理之前,我们先搞清楚比特币区块头的底层数据结构。我们说挖矿就是反复执行Hash函数的过程。 Hash函数是单输入单输出函数,输入数据为区块头。

如上,我们的一次性挖矿是对上述6个字段80字节进行两次SHA256的过程,输出结果固定为32字节(二进制256位)
以上6个字段不同,
固定:
1、 nVersion 这个字段是在比特币系统升级的时候改变的,所以当一个新的区块产生时,我们认为这个字段没有变化
2、hashPrevBlock 依赖于前一个区块头的hash值,生成这个字段对于新区块也不变
3、nBits 友好谜题难度系数,每2016个区块,根据算法重置该字段
变量:
4、hashMerkleRoot 包含了区块中所有交易计算出来的 Merkle 根 Hash。我们可以更改交易的输入、调整订单和 Coinbase 交易。这个值
5、nTime的合理出块时间值的范围是有限的,不能太早也不能太早,否则会被认为是无效的。理论上,当前出块时间可以早于上一个出块时间
6、nNonce 4 个字节,提供 2^32 个可能的值
根据Hash函数的特性,上述三个字段的任何微小变化都会导致Hash结果发生巨大变化。在 CPU 挖矿时代,nNonce 的 4 字节完全满足需求,但随着 GPU 挖矿的出现,4 字节的值可能无法满足需求,所以缺席者的注意力转向了 hashMerkleRoot

挖矿的逻辑如下:
1、打包交易,检索待处理的交易内存池,自由选择交易打包成新区块。矿工可以任意选择,可以选择空块,但不能无限选择,因为每个块都有容量限制(目前是1M)。最合理的策略是按费用排序,这样你就可以获得最多的交易费用。
2、构建 Coinbase。确定该区块包含的交易集后,即可统计该区块的总交易费用。结合输出规则,矿工可以计算出自己的区块收益。
3、计算hashMerkleRoot,构建Merkle树
4、填写其他字段,构建完整的区块头
5、对区块头进行SHA256操作
6、检查,如果满足难度规则,则全网广播; SHA256操作,即重复步骤4-6。
合格区块验证:
SHA256D(区块头) < F(nBits)
SHA256D(Blockheader)是本次挖掘的结果,F(nBits)是难度对应的目标值,都是256位,都当作大整数,直接比较大小判断是否他们符合难度要求。
挖矿就像抛硬币。如果我们有 256 个带有序列号的硬币,那么一次挖矿就是将所有这些硬币都扔掉以填补空白。如果前N个币都是单挑的,说明本次挖矿成功。
CPU挖矿时代
setgenreate协议接口代表cpu挖矿时代
Satoshi Nakamoto 在白皮书 Digital Democracy Ideas 中描述了“一个 cpu 一票”。挖矿功能集成在第一版客户端中。数据同步后,即可开始挖掘。我们有两种方式开始挖矿:
1、配置文件 gen=1 ,然后启动客户端进行挖矿
2、打开调试窗口,在命令行输入setgenerate true 2,开始挖矿
单核cpu的sha256算法是2MH/s(1秒100W这个Hash),按照创建新块的时间是10分钟,一共100W * 68 * 10 = 6亿次Hash尝试, nNonce 提供 2^32 个可能的值
足够满足需求
GPU挖矿时代
getwork协议代表GPU挖矿时代,GPU挖矿,挖矿程序与节点客户端分离,区块链数据与挖矿组件分离
CPU挖矿,使用客户端挖矿,需要先下载完整的数据,当我们有多台电脑时,不需要每台电脑都下载完整的数据,我们只要保证至少有一台电脑保存完整即可数据。同时,GPU挖矿时代的到来也需要一个协议来与客户端节点进行交互。
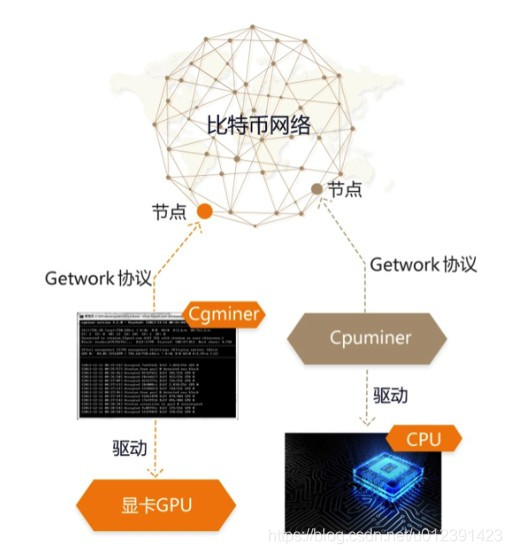
getwork的设计思路是节点客户端构建区块,负责1-3步挖矿,然后将区块头数据发送到外部挖矿程序负责4-6步。挖矿程序遍历nNonce进行挖矿。验证通过后,交付给节点客户端。节点客户端验证通过后,向全网广播。
区块头共80个字节,nVersion、hashPrevBlock、nBits和hashMerkleRoot 4个字段共72个字节必须由节点客户端提供。挖矿程序主要是增量遍历nNonce,必要时可以微调nTime字段。
gpu的sha256计算能力比cpu高很多,一般在200M-1G之间,所以nNonce提供了4G的选项,尝试完成只需要4秒,所以gpu可以适当调整ntime
数据节点客户端提供RPC接口getwork。该接口有一个可选参数。如果没有参数,就是申请数据;如果有参数,就是提交数据。

数据字段:共128字节(80个块头字节+48个补码字节),sha256会将输入数据处理成分片,要求是64的整数倍,块头数据不符合规则,所以需要补全数据。实际上不需要提供完整的数据;可能不提供 nNonce 字段,GPU 将采用自己的值。
目标字段:哈希难度目标字段,使用小头存储,需要翻转使用,外部程序可以通过数据和目标开始挖掘
中态字段:sha256拆分输入数据,前64字节数据固定比特币挖矿网站,节点已经为我们计算好前64个字段的hash值
hash1字段:每次挖矿需要执行两次sha256,第一次hash后有32个字段,需要使用hash1补全
外部程序不带参数调用getwork,节点客户端构造新区块并保存在内存中,以hashMerkleRoot为唯一标识,下一个区块被挖出时,地图清零
当外部程序挖出合格区块时,会通过getwork将修改后的数据返回给节点客户端。
ASIC挖矿时代
getBlockTemplate 协议标志着 ASIC 挖矿时代。矿池通过getBlockTemplate协议与节点客户端交互,通过stratum[ˈstreɪtəm]协议与缺席者交互。这是典型的矿池模式。
与getWork协议不同,getBlockTemplate协议允许矿工自行构建区块,节点客户端和挖矿完全分离。对于getwork协议,区块链是一个黑盒子,它只需要负责修改nNonce4字节的数据;对于getBlockTemplate来说,区块链是透明的,拥有挖矿的所有信息,包括待确认的交易池,可以自行打包。交易。
目前情况下,待确认的交易池有几万个订单,每个区块都是满的(1M)。因此getBlockTemplate的接口交互数据大小约为1.5M。与 getWork 协议非常不同。

Transactions,交易集合,不仅给出了每笔交易的十六进制数据,还给出了hash、交易费用等信息。
Coinbaseaux,如果你有什么信息想写入区块链,就放在这个字段,类似于中本聪的创世区块声明。
Coinbasevalue,挖掘下一个区块的最大收益值,包括新币的发行和交易费用。如果矿工在 Transactions 字段中包含所有交易,则该值可以直接用作 coinbase 输出。
Mintime,指下一个区块的最小时间戳,Curtime指当前时间,这两个时间作为矿工调整nTime字段的参考
高度,下一个区块的难度,目前协议规定这个值要写入coinbase中的指定位置。